2025/8/26 Informe de incidente: comportamiento anómalo de zbpack al reimplantar
 Pan
PanEn fechas recientes, debido a la retirada de la infraestructura existente de zbpack v1, Zeabur está distribuyendo a todos los usuarios la nueva generación del sistema de construcción (zbpack v2). Durante el proceso de actualización han surgido problemas de compatibilidad. En esta entrada explicamos las causas, cómo los hemos abordado y qué puedes hacer para mitigar el problema si te afecta.
¿Por qué estamos desplegando totalmente la nueva generación del sistema de construcción?
Así funciona la infraestructura de compilación detrás de Zeabur:
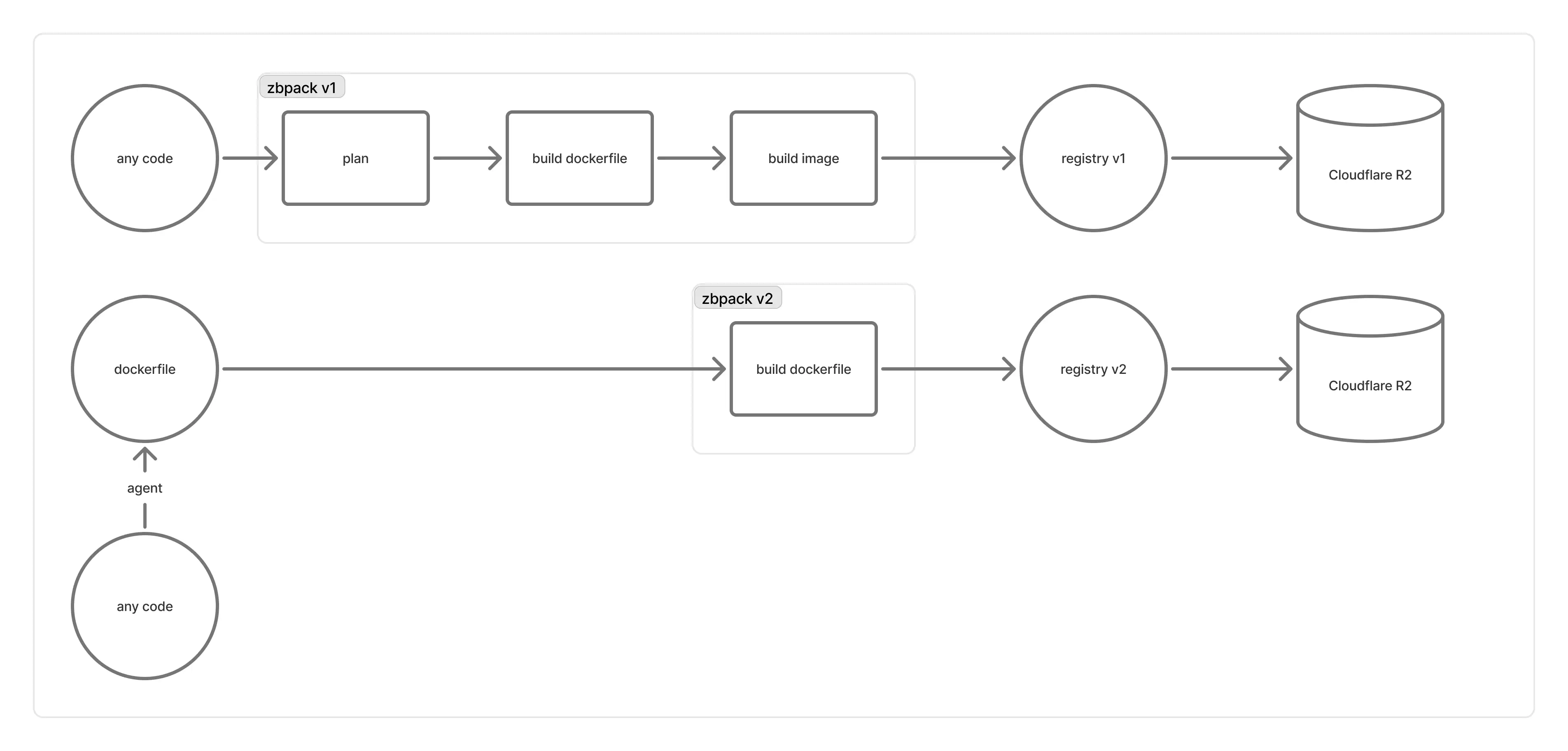
El «registry v1» estaba basado en el registro de distribution/distribution. Los diversos problemas que ocasionaba nos impulsaron a migrar a un «registry v2» diseñado por nosotros:
- Al principio seguíamos un modelo acoplado a la máquina de compilación (una máquina de compilación por cada registro). Como estas máquinas eran de corta duración y no había una manera fiable de obligar a que «los contenedores de una máquina se conectaran únicamente a su propio registro», a veces el registro terminaba antes que el contenedor de compilación, provocando fallos (y los reintentos no ayudaban mucho).
- Más tarde migramos el registro a máquinas de mayor duración y dejamos que los contenedores de las máquinas de compilación se conectaran a un registro tras un balanceador de carga. Sin embargo, al escribir el manifiesto de la imagen, el registro que subía los blobs podía no haber terminado realmente la subida o Cloudflare R2 sufría latencias al actualizar, lo que llevaba a errores
blob unknowny a rechazar la subida del manifiesto, impidiendo el pull de la imagen al arrancar. - Además,
distribution/distributionfavorece la desduplicación global de blobs, lo que impide saber qué blobs son prescindibles sin leer todos los manifiestos. La herramienta oficial de garbage collection exige detener el servicio (stop-the-world) y, a la escala del registro de Zeabur, es inviable; R2 acumuló una gran cantidad de blobs, causando problemas serios de rendimiento. - Muchos usuarios también nos informaron de velocidades de subida muy lentas a través del registry v1.
Diseñamos el registry v2 para que, tras construir una imagen OCI, se suba directamente a un bucket de R2. Luego, mediante Cloudflare Workers, implementamos una API de solo lectura que transforma la estructura OCI del bucket en un Pull API conforme a la Especificación de Distribución de OCI. Con ello logramos grandes mejoras de rendimiento, maximizamos la eficiencia de las subidas multipart y evitamos los problemas del registro anterior. A la vez, limitamos la desduplicación de blobs al interior de cada repositorio, permitiendo que «al eliminar un repositorio se pueda hacer GC de sus blobs asociados», simplificando enormemente el mantenimiento sin necesidad de stop-the-world.
Sin embargo, como se deduce de lo anterior, el flujo de push en el registry v2 cambia sustancialmente. Esta parte ya está implementada en zbpack v2, pero en zbpack v1, debido a su flujo de push más complejo y a la fuerte dependencia del CLI de buildkit para construir imágenes, resultaba difícil. Por ello, durante el último mes dejamos que los proyectos que seguían en zbpack v1 (registry v1) continuaran compilando con v1 y solo migrábamos manualmente a zbpack v2 cuando un usuario informaba que v1 no podía arrancar.
Cuando el registry v1 comenzó a resentirse cada vez más y la frecuencia de errores aumentó, el volumen de tickets creció tanto que nos vimos obligados a mover la parte de imágenes de zbpack v1 hacia zbpack v2.
¿Por qué el nuevo sistema de construcción ha tenido tantos problemas?
Quizá hayas notado que el repositorio de zbpack (v1) pasó de archivado a activo y recibió muchos cambios relacionados con Dockerfile. En realidad, esto era la preparación de una capa de compatibilidad para conectar zbpack v1 con zbpack v2.
Queríamos mantener la generación de Dockerfile de zbpack v1, pero sin usar su lógica de construcción integrada después, sino pasar a zbpack v2. Por ello, convertimos la generación de Dockerfile de v1 en una función pública y dejamos que el servicio de construcción la usara para producir el Dockerfile, que luego se envía a las máquinas de compilación que ejecutan zbpack v2.
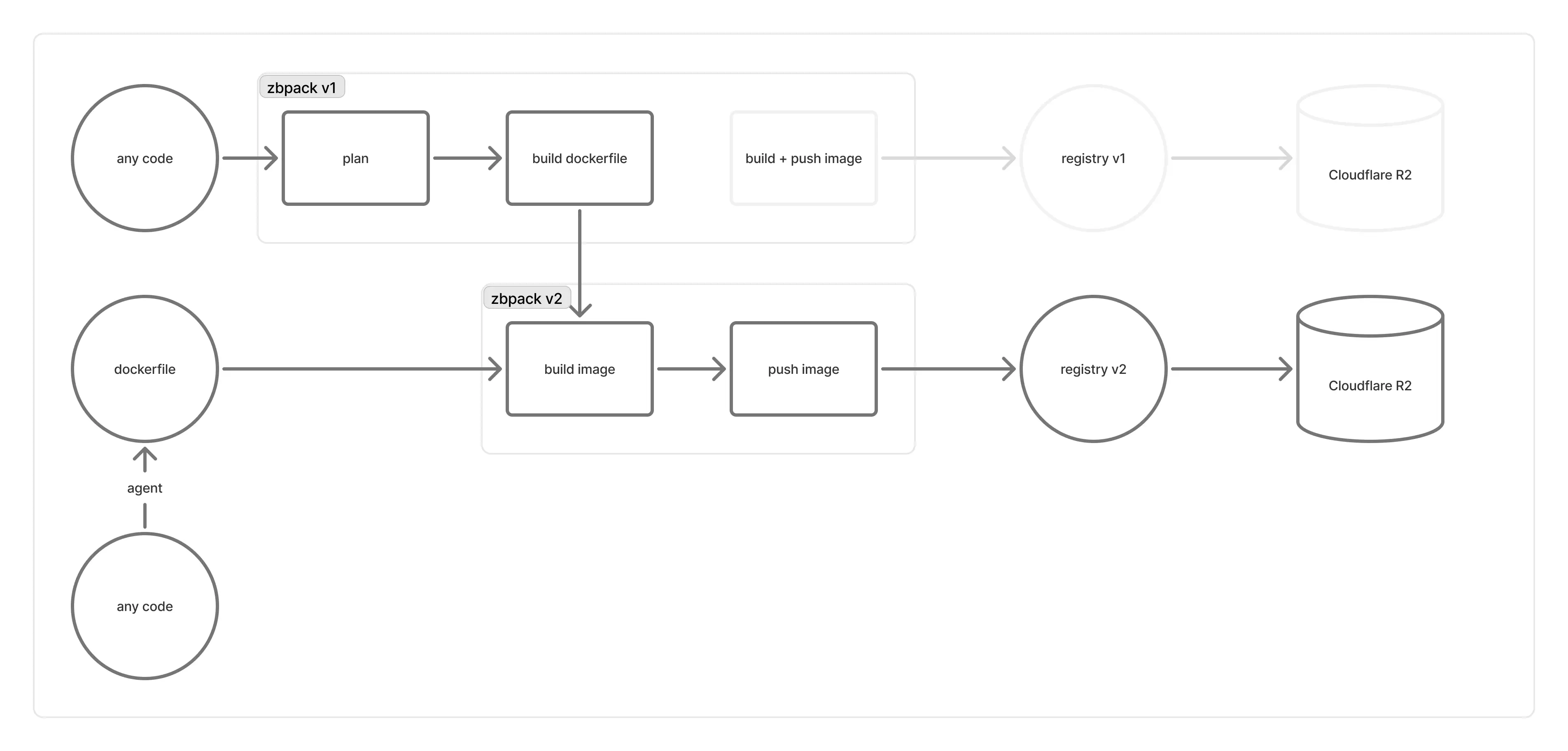
No obstante, zbpack v1 fue concebido inicialmente para funcionar dentro de la máquina de compilación y había muchas piezas que implementar o adaptar:
- zbpack v1 dependía de muchas variables de entorno y no podíamos cambiar las del servicio de construcción.
- zbpack v1 se diseñó como un CLI de ejecución única; conectarlo directamente al servicio de construcción podía activar lógicas internas de panic.
- La máquina de compilación de v1 proporcionaba numerosos parámetros especializados a zbpack v1 que debíamos replicar uno a uno en la capa de compatibilidad.
Implementamos la capa de compatibilidad de zbpack v1, portando el manejo que hacía la máquina de compilación al invocar a v1. La mayoría de los problemas evidentes (como la lectura de código) se resolvieron antes del despliegue global, y en pruebas internas en máquinas de test no observamos falsos positivos. También hubo ingenieros on-call monitorizando el impacto. Aun así, al desplegar en todo el parque surgieron problemas no contemplados. Por ejemplo:
- Las variables de entorno requeridas por zbpack no se pasaron correctamente, invalidando las variables que empiezan por
ZBPACK_. - El «directorio raíz» del proyecto no se transmitía bien a zbpack v1, que infería todo desde el root real de la máquina.
- La versión de zbpack v1 usada por la capa de compatibilidad introducía cambios importantes en la lógica de Dockerfile; las pruebas no lo cubrieron bien y el comportamiento de
ZBPACK_DOCKERFILE_NAMEno coincidía con el previo. - Muchos usuarios valoran ver el plan type y el plan meta; la capa de compatibilidad no los mostraba correctamente en los build logs como antes.
- El acceso al registry v2 desde China continental era muy lento.
Como algunos escenarios no tenían entorno de pruebas equivalente y retroceder podía tener un impacto mayor, durante las guardias optamos por corregir, probar y desplegar con rapidez, ofreciendo a la vez workarounds a los clientes. Entre el 26 y el 27 de agosto implementamos rápidamente la capa de compatibilidad completa de zbpack, añadimos la visualización de plan type y plan meta, y diseñamos una CDN específica para China continental para acelerar las descargas del registry v2.
Agradecemos a todos los clientes que reportaron problemas: nos ayudaron a descubrir casos límite no cubiertos por la capa de compatibilidad y nos empujaron a investigarlos y corregirlos.
¿Volverá a ocurrir este problema?
Los problemas mencionados arriba ya están implementados o corregidos en la capa de compatibilidad. Si encuentras otros huecos, abre un ticket y nuestros ingenieros lo revisarán.
Los problemas conocidos a día de hoy son:
- En nuevas implementaciones, el puerto externo puede volver al valor por defecto 8080. Seguimos investigando la causa. De forma temporal, puedes establecer manualmente
PORT=<puerto externo>(por ejemplo,PORT=8080). - Si implementas con Dockerfile y no se está leyendo correctamente, ve a «Ajustes» > «Dockerfile» y pega manualmente el contenido que desees usar. Aun así, como este problema debería estar ya corregido, te pedimos que abras un ticket para que podamos investigarlo.
En retrospectiva, las causas principales del incidente fueron:
- Muy pocos casos de prueba internos; faltaron tests sobre el directorio raíz y el nombre del Dockerfile. Pensamos erróneamente que «la capa de compatibilidad cubría todos los entornos» y lo tratamos como un cambio menor apto para despliegue global.
- Cualquier funcionalidad que cambie comportamientos (como la «capa de compatibilidad de zbpack v1») debe implementarse y gobernarse con un mecanismo de feature flags, como en zbpack v2, en lugar de un despliegue forzoso para todos.
- Falta de comprensión de las condiciones de red en China continental; extrapolamos la situación de red internacional y no implementamos la CDN por adelantado.
- Deberíamos haber realizado pruebas con un grupo reducido de clientes y recabado feedback antes.
Si te viste afectado por este incidente, podemos ofrecer créditos como compensación proporcional al tiempo de impacto. Seremos más cautelosos en futuros despliegues de esta funcionalidad y, nuevamente, gracias a todos quienes nos ayudaron a detectar problemas en la capa de compatibilidad.