
Docling
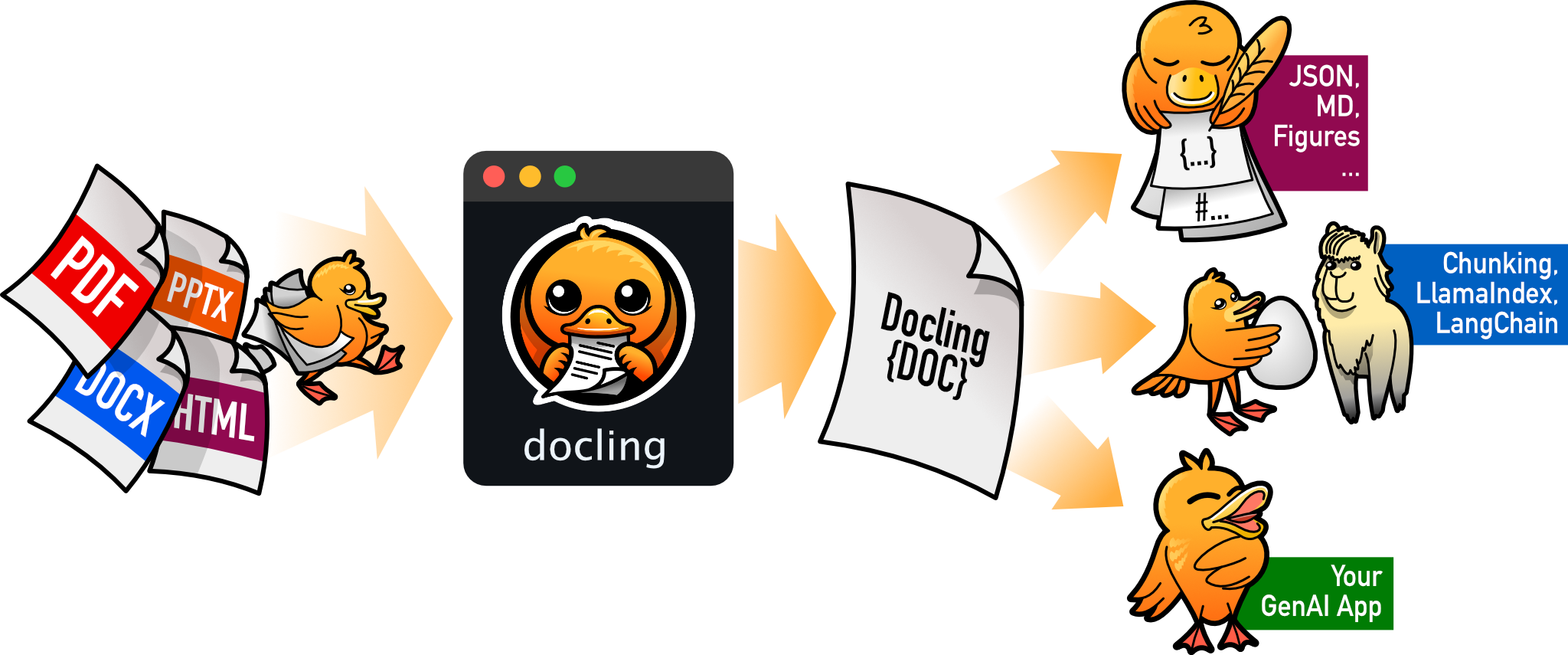
Docling is a document parsing API by IBM Research that converts PDF, DOCX, PPTX, HTML, and images into structured Markdown or JSON. Features an interactive Swagger UI for testing conversions. Stateless API — no external database required.
Services
Docling
A document parsing API by IBM Research. Converts PDF, DOCX, PPTX, HTML, images, and AsciiDoc into structured Markdown or JSON with high fidelity. Powered by AI models for layout analysis and table structure recognition.
What You Can Do After Deployment
- Visit your domain — the Swagger UI loads at
/docsfor interactive API testing - Convert PDFs — upload PDF files and get structured Markdown or JSON output
- Process DOCX/PPTX — convert Office documents with preserved structure
- Extract tables — AI-powered table structure recognition with cell-level accuracy
- Batch processing — convert multiple documents via the API
- OCR support — extract text from scanned documents and images
- Integrate via API — use the REST API from any programming language
API Example
curl -X POST "https://YOUR_DOMAIN/v1/convert/source" \
-F "file=@document.pdf" \
-H "accept: application/json"
Key Features
- PDF, DOCX, PPTX, HTML, image, AsciiDoc input support
- Markdown and JSON output formats
- AI-powered layout analysis (DocLayNet)
- Table structure recognition (TableFormer)
- OCR for scanned documents
- Metadata extraction
- Stateless — no database needed
License
MIT — GitHub