Guía de Selección de Bases de Datos 2025
Por fin, tomar la decisión tecnológica clave para tu startup será pan comido.
 Kyle Chung
Kyle ChungTL;DR
No existe una base de datos "única para todos". La habilidad de un desarrollador moderno no radica en dominar una sola base de datos, sino en saber qué herramienta sacar de la caja de herramientas para la tarea en cuestión. Incluso en un flujo de trabajo con soporte de IA, estas decisiones siguen siendo esenciales para escalar productos y servicios de manera eficiente y eficaz.
Al comprender las fortalezas principales de cada uno (Postgres para la potencia, MySQL para la confiabilidad, MongoDB para la flexibilidad, Redis para la velocidad y Supabase para la velocidad), puede crear aplicaciones más sólidas, escalables y exitosas.
Eligiendo su base de datos en 2025: una guía de PostgreSQL, MongoDB, Supabase y más
Toda gran aplicación se basa en una base sólida de datos, pero para los desarrolladores, elegir la base de datos correcta puede parecer como navegar por un campo minado. Una elección incorrecta al principio puede provocar cuellos de botella en el rendimiento, dolores de cabeza en el desarrollo y un mundo de dolor en el futuro. El panorama es vasto, con una vertiginosa variedad de opciones, cada una de las cuales afirma ser la mejor.
La verdad es que no existe una única "mejor" base de datos. La verdadera pregunta es: ¿Cuál es la base de datos adecuada para su proyecto específico?
Esta guía desmitificará las opciones más populares de la actualidad. Exploraremos la arquitectura de bajo nivel de titanes como PostgreSQL y MySQL, comprenderemos la flexibilidad de NoSQL con MongoDB, sentiremos la velocidad de Redis y veremos cómo las plataformas modernas como Supabase están cambiando el juego. Al final, tendrá un marco claro para tomar la decisión correcta para su próximo proyecto.
Comprender las principales categorías de bases de datos
Antes de sumergirnos en nombres específicos, comprendamos las principales familias a las que pertenecen.
- SQL (bases de datos relacionales): Piense en una colección de hojas de cálculo de Excel altamente organizadas con reglas estrictas. Los datos se almacenan en tablas con filas y columnas, y las relaciones entre tablas están claramente definidas. Esta estructura garantiza una alta integridad y coherencia de los datos, lo que la convierte en una opción confiable para datos predecibles.
- NoSQL (bases de datos no relacionales): Piense en un archivador flexible donde puede almacenar diferentes tipos de documentos sin tener que predefinir su estructura. Esta categoría es increíblemente diversa e incluye almacenes de documentos (como MongoDB) y almacenes de clave-valor (como Redis). Se destaca en el manejo de grandes volúmenes de datos no estructurados y en la escalada horizontal.
- DBaaS (base de datos como servicio): Este no es un nuevo tipo de base de datos, sino una forma moderna de usar una. Un proveedor de DBaaS le brinda una "base de datos con baterías incluidas": se encargan del servidor, la configuración, las copias de seguridad y, a menudo, agregan potentes capas en la parte superior, como autenticación y API autogeneradas, lo que le permite concentrarse únicamente en crear su aplicación.
Los contendientes: una mirada más cercana
Ahora conozcamos a nuestros jugadores.
PostgreSQL: el todoterreno potente y extensible
PostgreSQL es una potente base de datos de código abierto que funciona con un modelo cliente-servidor, donde un proceso central "Postmaster" gestiona las conexiones entrantes creando procesos separados para cada usuario. Esto garantiza la estabilidad y el aislamiento. En esencia, los datos se almacenan en archivos en su disco, organizados en tablas y acelerados por índices, de forma muy parecida a un archivador digital con un útil catálogo de tarjetas. Para manejar a muchos usuarios a la vez sin conflictos, utiliza ingeniosamente un sistema llamado Control de concurrencia de múltiples versiones (MVCC), que le da a cada usuario una "instantánea" consistente de los datos, lo que permite una alta concurrencia sin bloquear a otros.
MySQL y MariaDB: los caballos de batalla fiables y probados en batalla
MySQL funciona con una arquitectura cliente-servidor clásica en la que el proceso del servidor central gestiona todas las instrucciones de la base de datos. Su característica arquitectónica clave es su modelo de motor de almacenamiento conectable, que separa el procesamiento de consultas del almacenamiento de datos. Esto le permite elegir diferentes "motores de almacenamiento" (como el popular InnoDB, seguro para transacciones) para diferentes tablas según sus necesidades. MariaDB, una bifurcación de MySQL impulsada por la comunidad, comparte esta arquitectura central pero continúa desarrollando sus propios motores de alto rendimiento, lo que convierte a ambas bases de datos en caballos de batalla increíblemente versátiles y fiables que impulsan una parte masiva de la web.
MongoDB: el rey de los datos flexibles basados en documentos
MongoDB es una base de datos NoSQL líder que almacena datos en documentos flexibles similares a JSON utilizando un formato codificado en binario llamado BSON para mayor eficiencia. En lugar de tablas, los datos se organizan en "colecciones" sin un esquema forzado, lo que ofrece una inmensa flexibilidad. Para manejar grandes conjuntos de datos, MongoDB está diseñado para la escalabilidad horizontal a través de la "fragmentación", que divide los datos en varios servidores. Su motor de almacenamiento, WiredTiger, utiliza el control de concurrencia a nivel de documento y el almacenamiento en caché en memoria para garantizar operaciones de lectura y escritura de alto rendimiento.
Redis: el demonio de la velocidad en memoria
Redis (Remote Dictionary Server) es un almacén de clave-valor en memoria, lo que significa que contiene principalmente todo el conjunto de datos en la RAM de su computadora. Este es el secreto de su rendimiento ultrarrápido. Arquitectónicamente, Redis es de un solo subproceso y utiliza un bucle de eventos para manejar las solicitudes, gestionando de manera eficiente a los clientes simultáneos sin la sobrecarga del subproceso múltiple. Si bien es más que un simple almacén de clave-valor, ya que admite estructuras de datos ricas como listas, conjuntos y hashes, su principal fortaleza radica en su velocidad, lo que lo convierte en una opción incomparable para el almacenamiento en caché y las tareas en tiempo real.
Supabase: el moderno backend como servicio en Postgres
Supabase no es una nueva base de datos, sino una plataforma amigable para los desarrolladores construida directamente sobre PostgreSQL. Cada proyecto de Supabase es una instancia dedicada de Postgres, pero con un potente conjunto de herramientas de código abierto superpuestas. Esto incluye un sistema de autenticación que utiliza la propia seguridad a nivel de fila de Postgres, una puerta de enlace de API que genera automáticamente API RESTful a partir de su esquema y un servidor en tiempo real que transmite los cambios de la base de datos a los clientes suscritos. Le brinda el poder de Postgres con la comodidad de un BaaS moderno.
Cara a cara: la matriz de comparación
| Característica | PostgreSQL | MySQL/MariaDB | MongoDB | Redis | Supabase |
|---|---|---|---|---|---|
| Modelo de datos | Relacional (SQL) | Relacional (SQL) | NoSQL (Documento) | NoSQL (Clave-Valor) | Relacional (SQL) |
| Caso de uso principal | Consultas complejas, integridad de datos, propósito general | Aplicaciones web, comercio electrónico, tareas de lectura intensiva | Datos no estructurados, big data, aplicaciones móviles | Almacenamiento en caché, sesiones, tablas de clasificación en tiempo real | Desarrollo rápido, MVP, proyectos que necesitan autenticación/API |
| Escalabilidad | Vertical (fuerte), Horizontal (complejo) | Vertical (fuerte), Horizontal (complejo) | Horizontal (nativo) | Horizontal (nativo) | Vertical (gestionado) |
| Esquema | Forzado y estricto | Forzado y estricto | Flexible y dinámico | Sin esquema | Forzado y estricto |
| Experiencia del desarrollador | Excelente, pero requiere configuración | Muy sencillo y ampliamente compatible | Fácil de empezar, el esquema flexible es ideal para los desarrolladores | API simple, muy rápida | La más alta. Experiencia "con todo incluido". |
Cómo elegir una base de datos: una guía práctica de decisiones
Entonces, ¿cuál es para ti? Analicémoslo según sus necesidades.
- Si sus datos están muy estructurados y la integridad no es negociable...
- ...entonces comience con PostgreSQL. Su sólido conjunto de funciones y su cumplimiento de los estándares SQL lo convierten en una apuesta segura y potente para aplicaciones financieras, datos científicos y cualquier sistema complejo donde la coherencia de los datos es primordial.
- Si está creando una aplicación web tradicional (como un blog o un sitio de comercio electrónico) y necesita algo confiable y fácil...
- ...entonces MySQL o MariaDB son opciones fantásticas. Tienen una comunidad masiva, son fáciles de alojar y están probados en batalla por años de potenciar una gran parte de la web.
- Si sus datos no están estructurados, evolucionan con frecuencia o necesita escalar masivamente...
- ...entonces MongoDB es su mejor amigo. Su modelo de documento flexible es perfecto para sistemas de gestión de contenido, datos de IoT y aplicaciones donde la forma de los datos no se conoce de antemano.
- Si necesita una velocidad vertiginosa para el almacenamiento en caché, estadísticas en tiempo real o la gestión de sesiones de usuario...
- ...entonces no busque más allá de Redis. No está destinado a ser su base de datos principal, pero como una capa ultrarrápida sobre ella, es insuperable.
- Si desea crear y lanzar un proyecto lo más rápido posible sin administrar un backend...
- ...entonces Supabase es el claro ganador. Le brinda el poder de Postgres pero se encarga de las partes tediosas como las API, la autenticación y las funciones en tiempo real por usted, lo que lo hace ideal para nuevas empresas, proyectos paralelos y MVP.
Cómo implementar una base de datos con un solo clic con Zeabur
Implementar con el Agente de Zeabur (Recomendado)
- Iniciar implementación: El usuario inicia el proceso de implementación de Supabase en la plataforma Zeabur. El asistente de IA confirma que ha encontrado la plantilla de Supabase y generará automáticamente valores iniciales para el nombre de usuario y el prefijo de dominio.
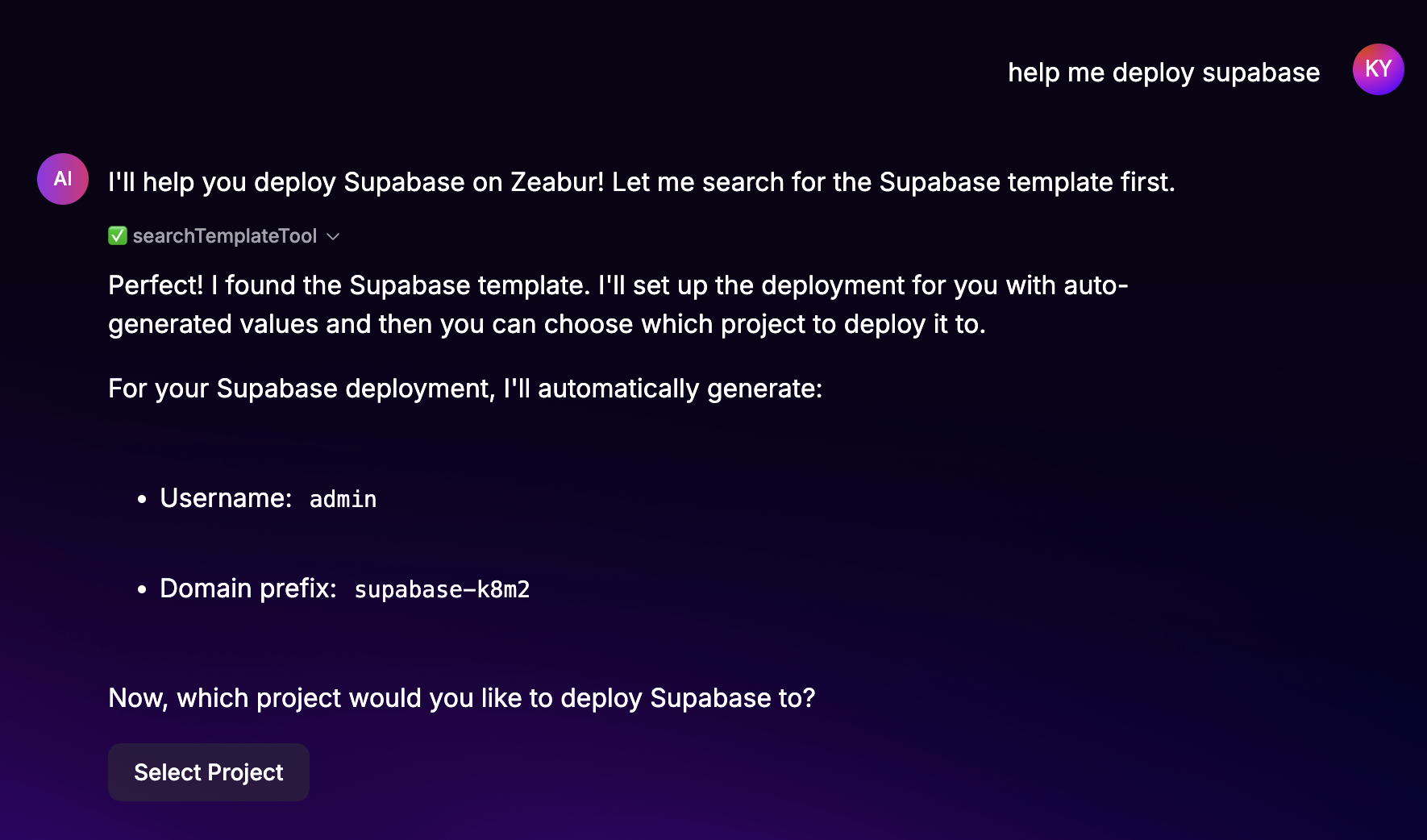
- Seleccionar proyecto: Se le solicita al usuario que elija a qué proyecto existente implementar Supabase. Se muestra una lista de proyectos disponibles.
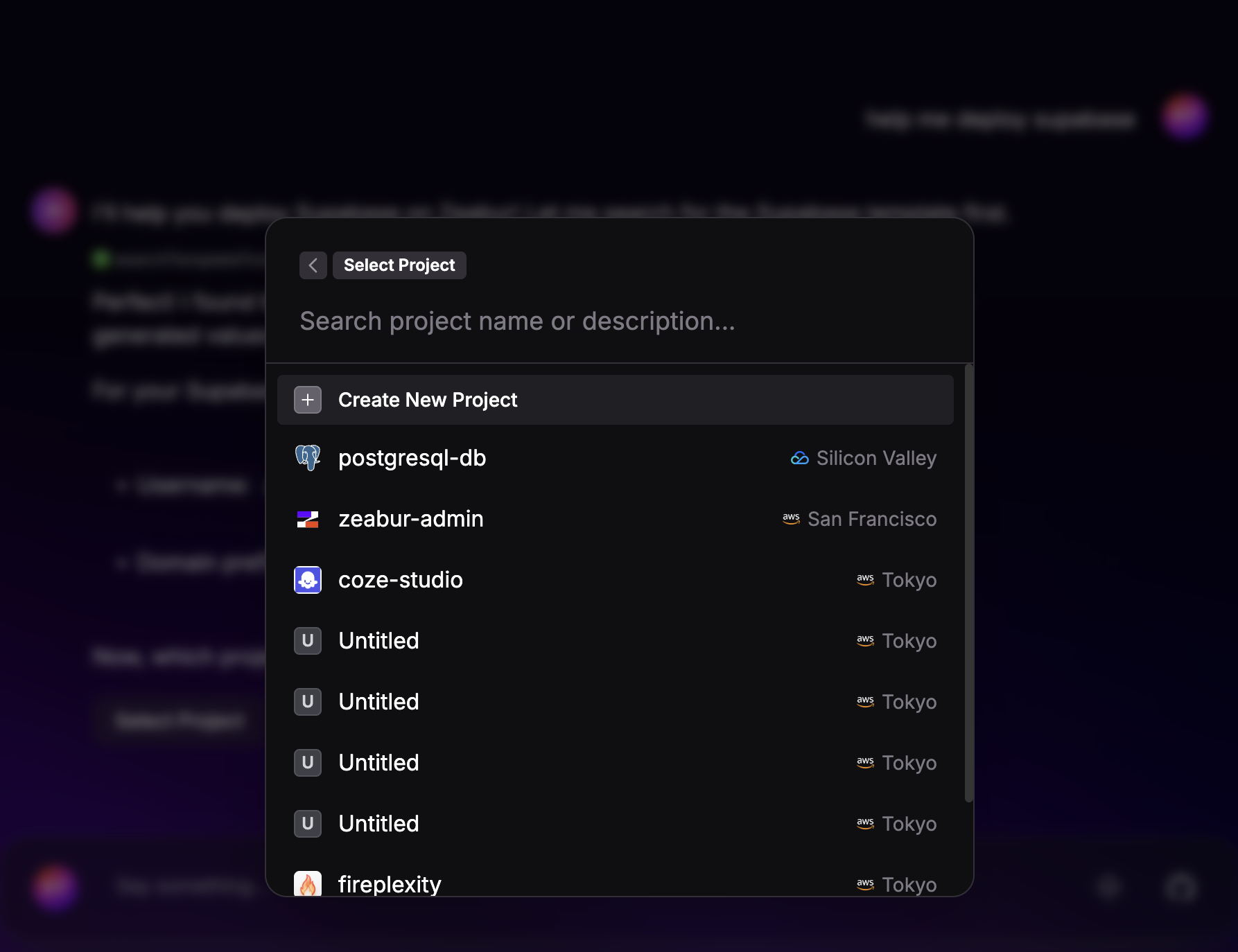
- Crear nuevo proyecto: En lugar de seleccionar un proyecto existente, el usuario decide crear uno nuevo para esta implementación.

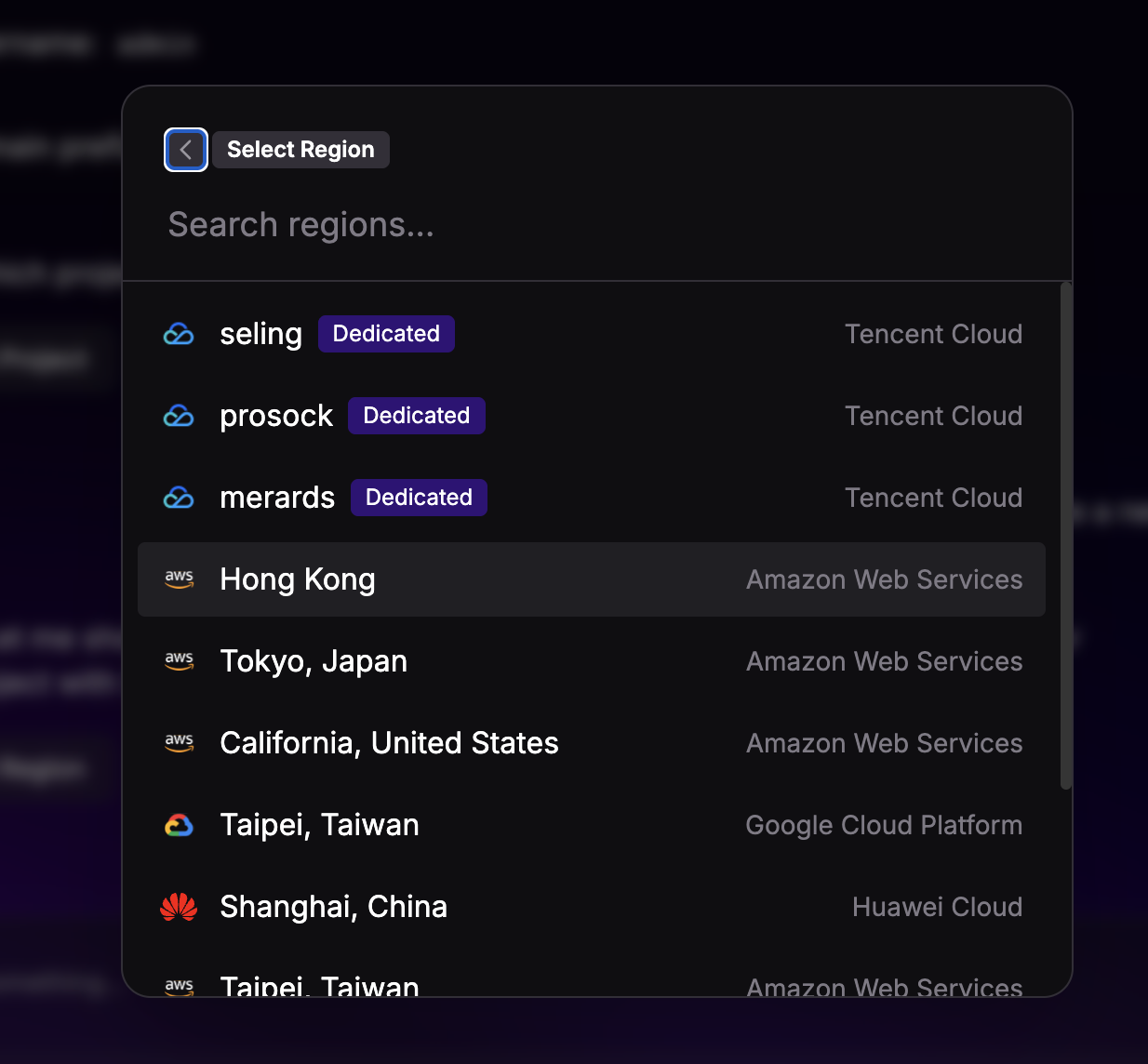
- Seleccionar región: A continuación, se le presenta al usuario una lista de regiones geográficas y proveedores de nube disponibles para alojar el nuevo proyecto y sus servicios. Seleccionan "Hong Kong" en Amazon Web Services.
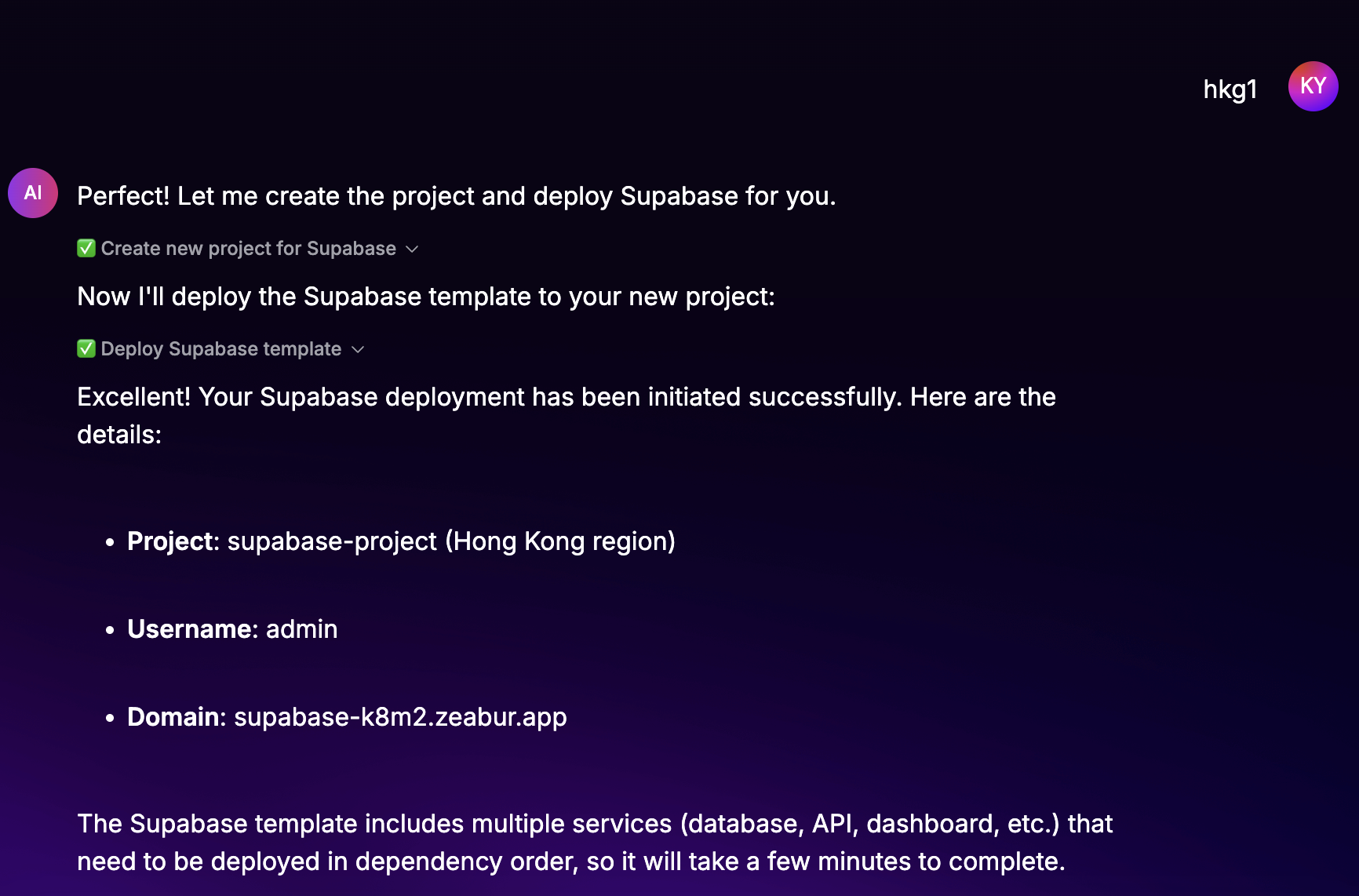
- Confirmación de implementación: El asistente de IA confirma que el nuevo proyecto se ha creado y que la implementación de la plantilla de Supabase se ha iniciado correctamente. Proporciona los detalles finales, incluido el nombre del proyecto, la región, el nombre de usuario y el dominio completo.
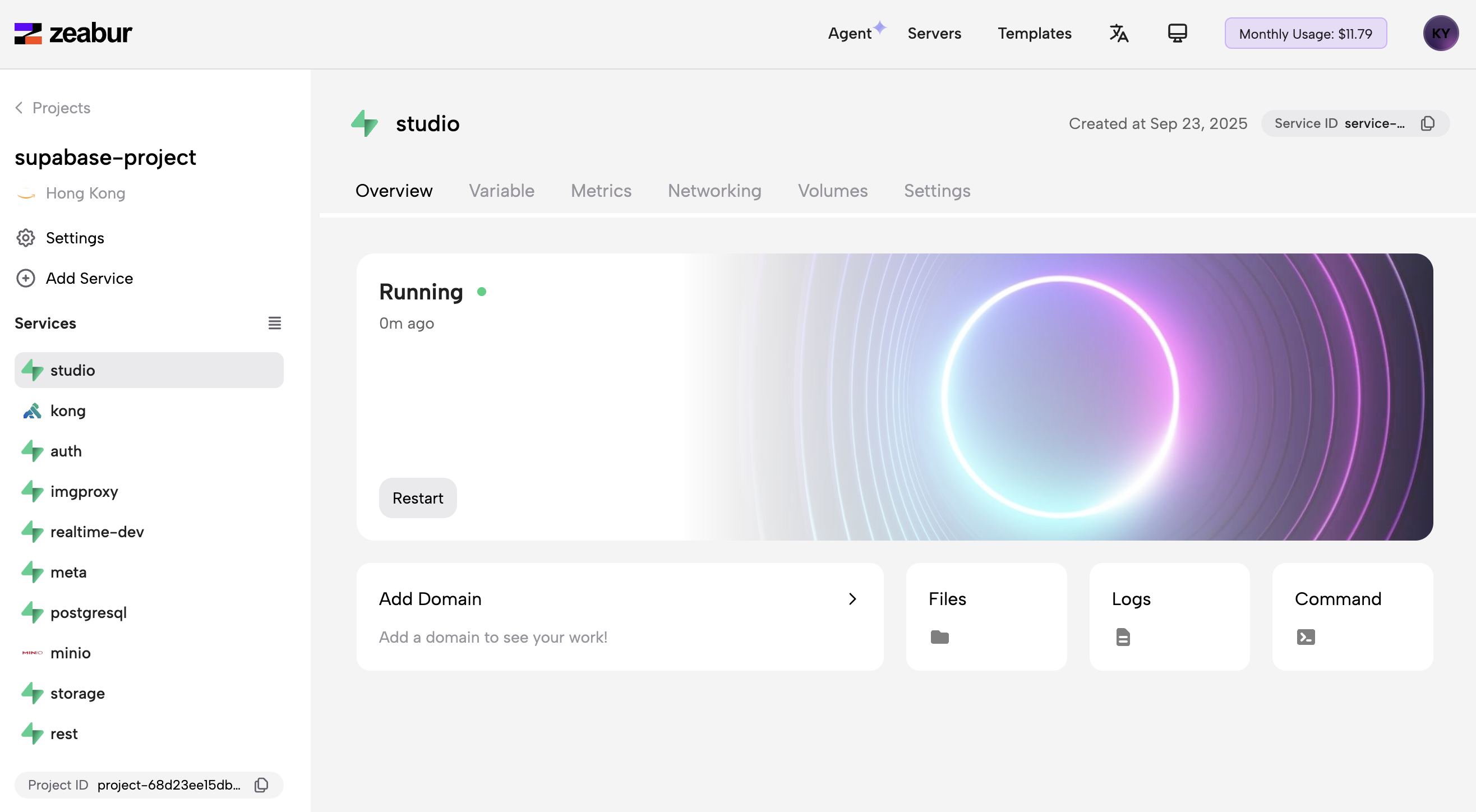
- Ver servicios: La imagen final muestra al usuario navegando con éxito a su nuevo "proyecto-supabase" en el panel de control de Zeabur. El servicio "studio" se está ejecutando y todos los demás servicios de Supabase (como auth, kong, postgresql, etc.) se enumeran como parte del proyecto.
Configuración manual con plantillas preconstruidas
Aquí está el flujo de trabajo paso a paso ilustrado por las imágenes:
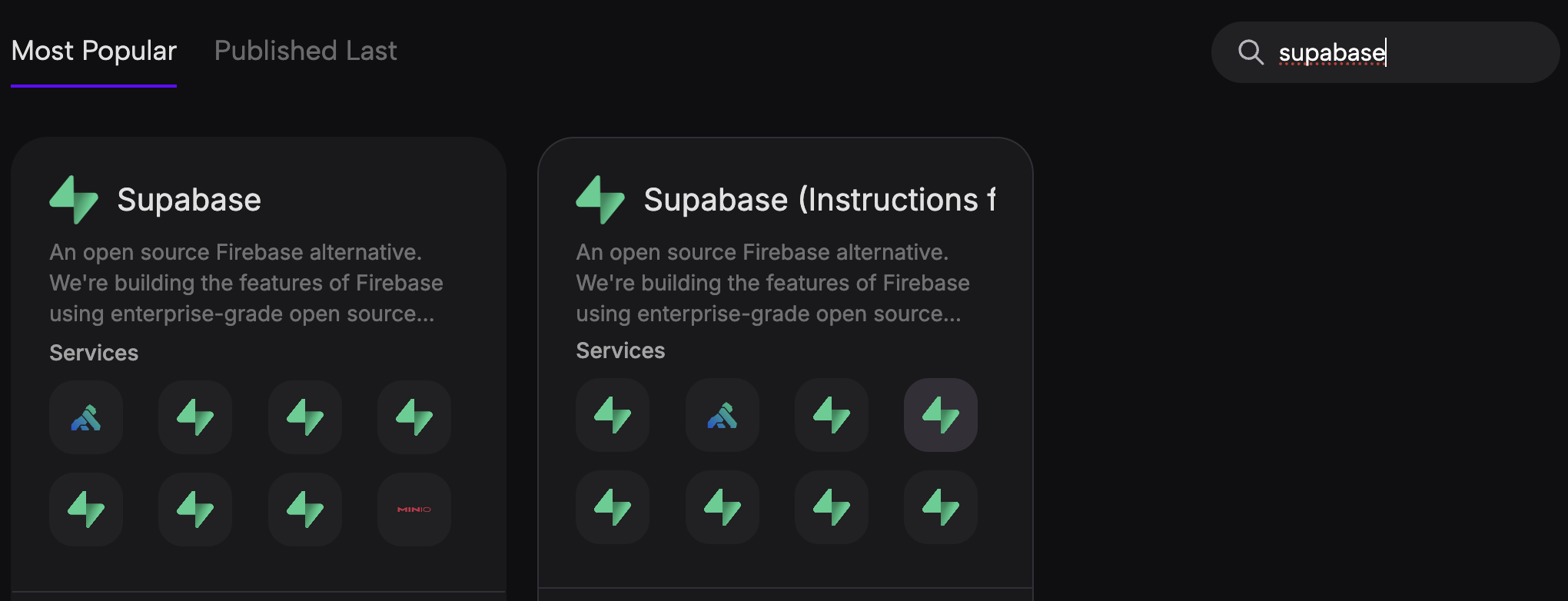
- Navegar a plantillas: El usuario está en el sitio web de Zeabur y navega a la sección "Plantillas" para encontrar plantillas de aplicaciones preconfiguradas.

- Buscar Supabase: El usuario utiliza la barra de búsqueda para buscar específicamente la plantilla "Supabase" entre las opciones disponibles.
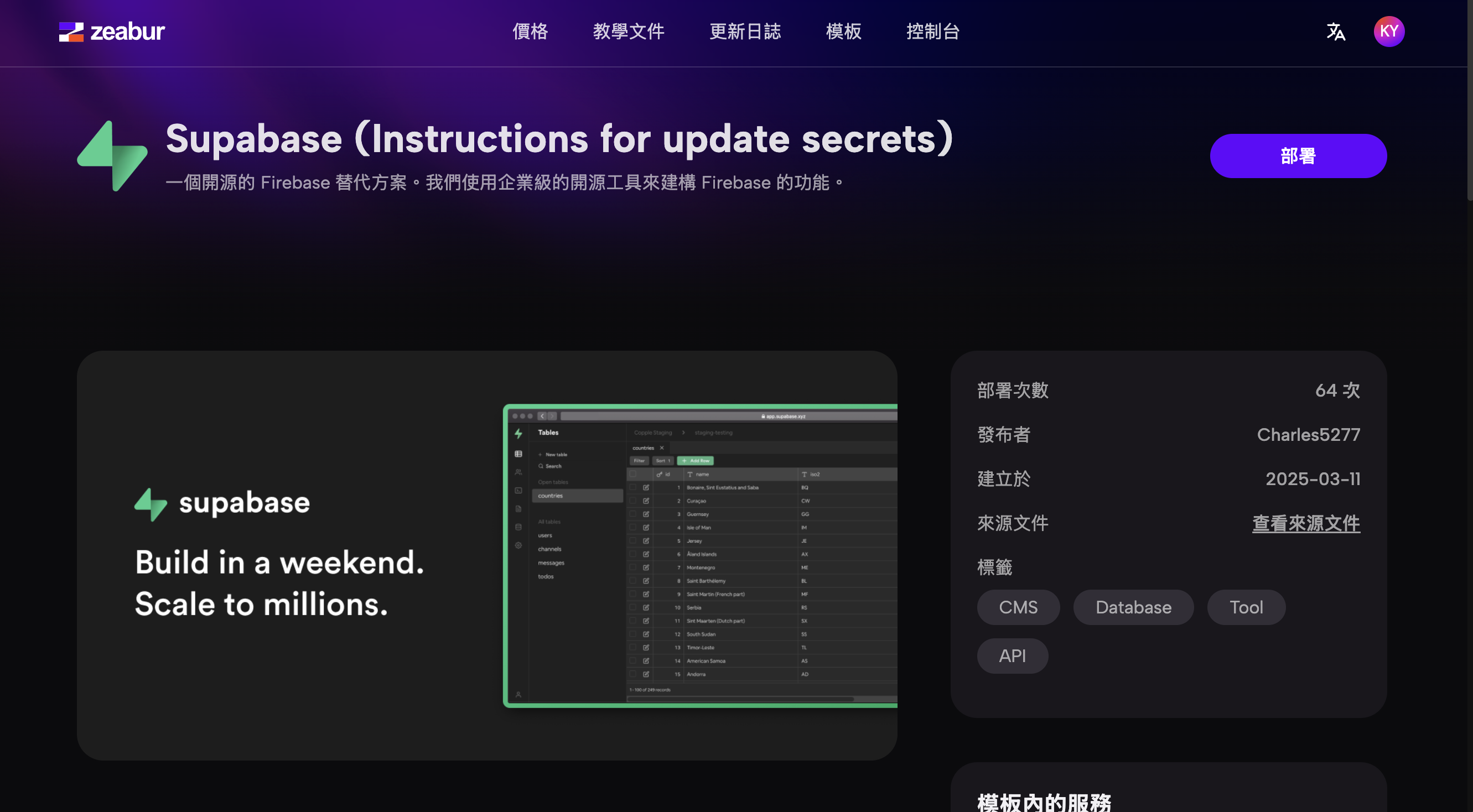
- Seleccionar la plantilla: Después de encontrar la plantilla "Supabase (Instrucciones para actualizar secretos)", el usuario hace clic en ella para ver sus detalles e iniciar el proceso de implementación.
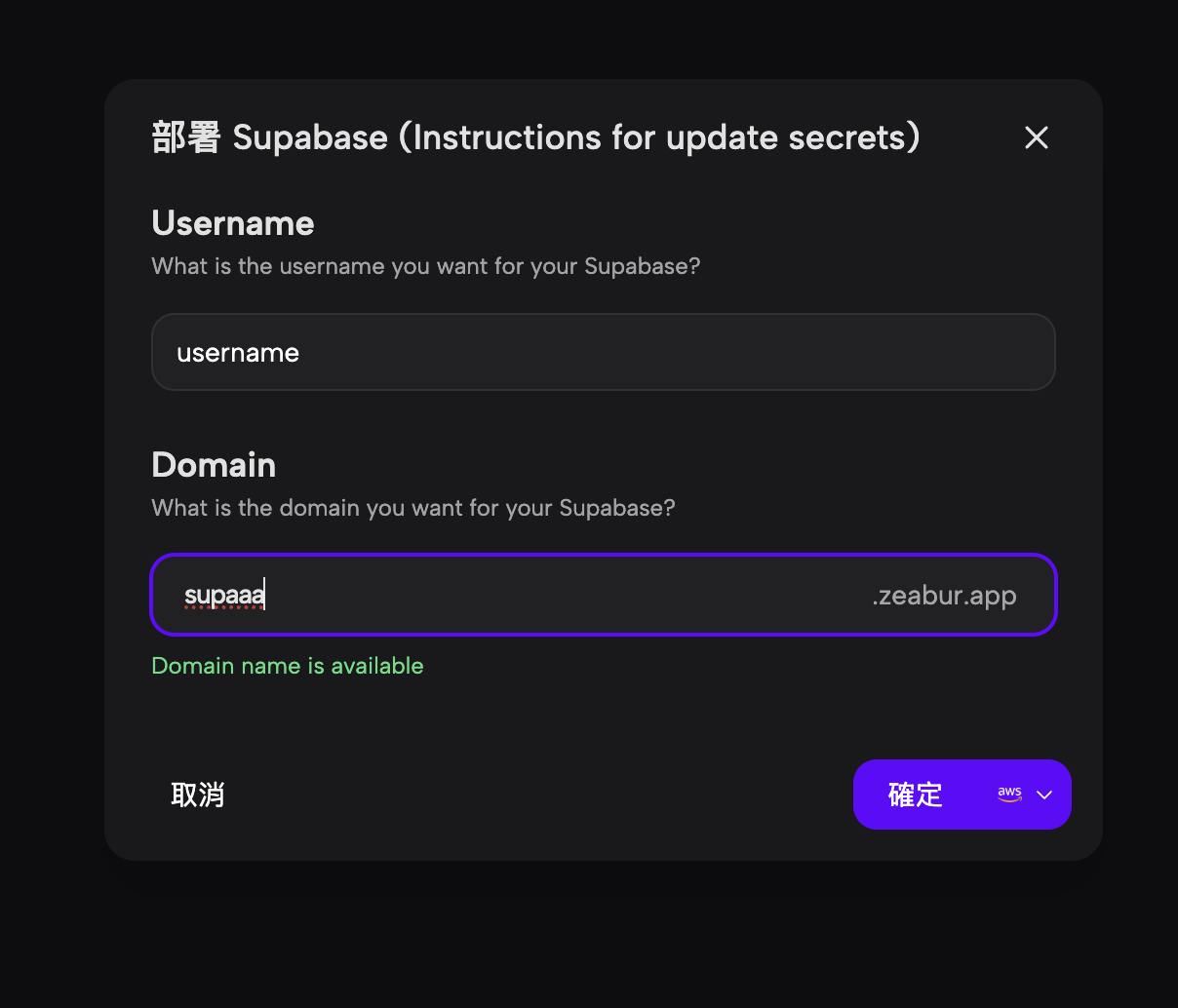
- Configurar implementación: Aparece un modal de configuración que le solicita al usuario que ingrese un nombre de usuario deseado y un prefijo de dominio para su instancia de Supabase.
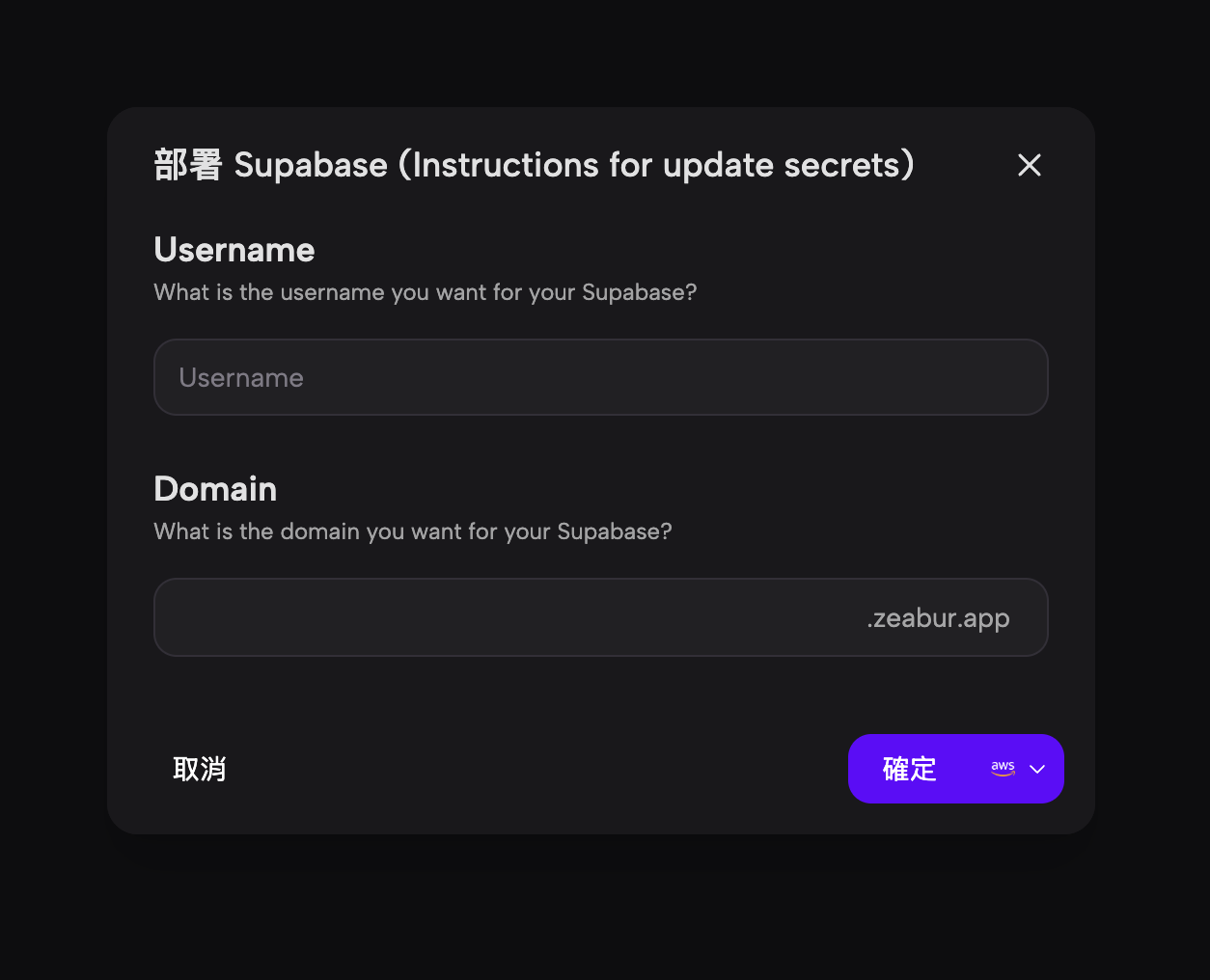
- Proporcionar detalles: El usuario completa la información requerida, ingresando "username" y "supaaa" para el prefijo de dominio, y el sistema confirma que el dominio elegido está disponible.
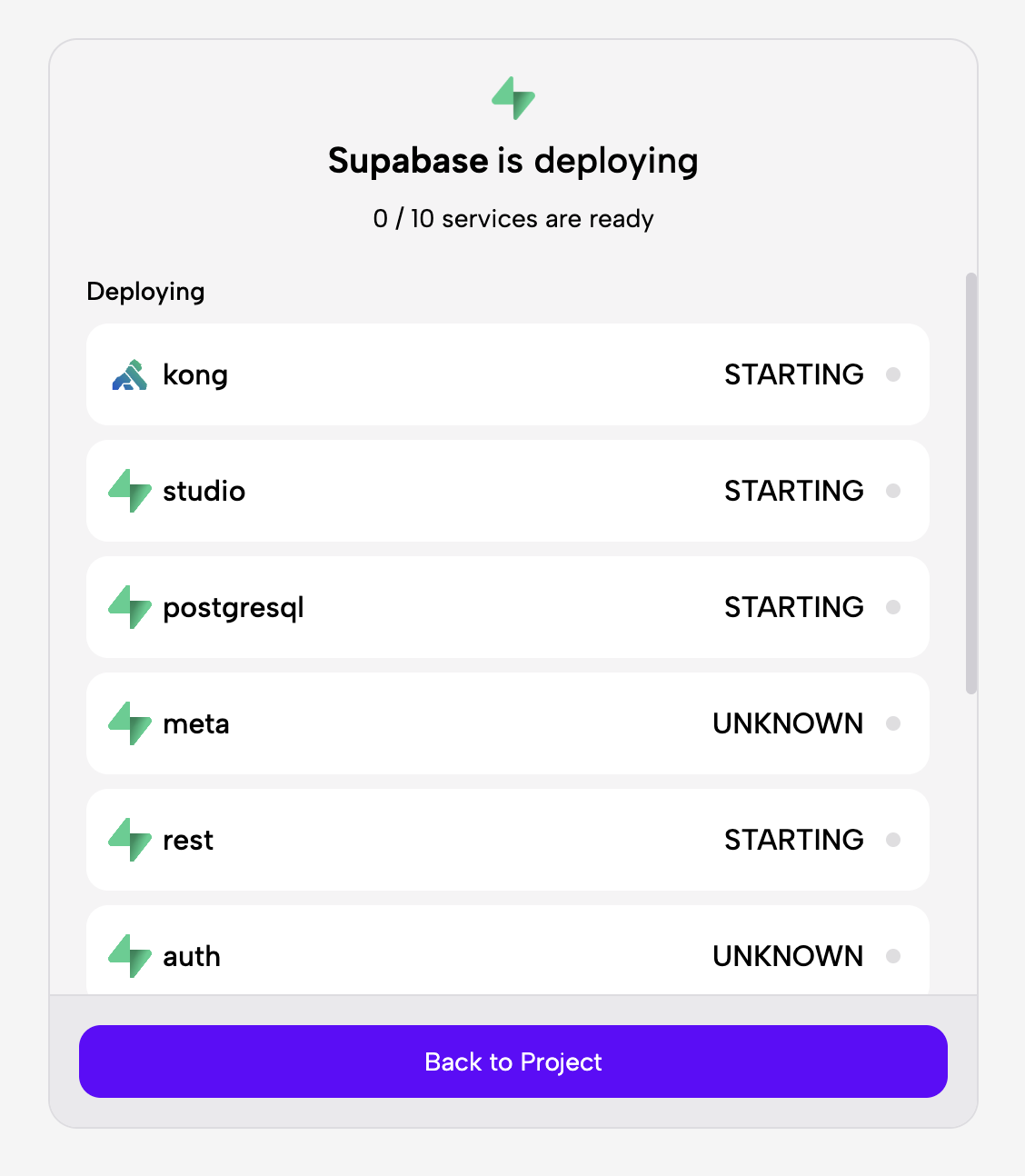
- Iniciar implementación: Después de confirmar los detalles, el usuario inicia la implementación. Aparece una pantalla de estado que muestra el progreso a medida que se aprovisiona cada uno de los 10 servicios requeridos por Supabase (como kong, studio, postgresql).
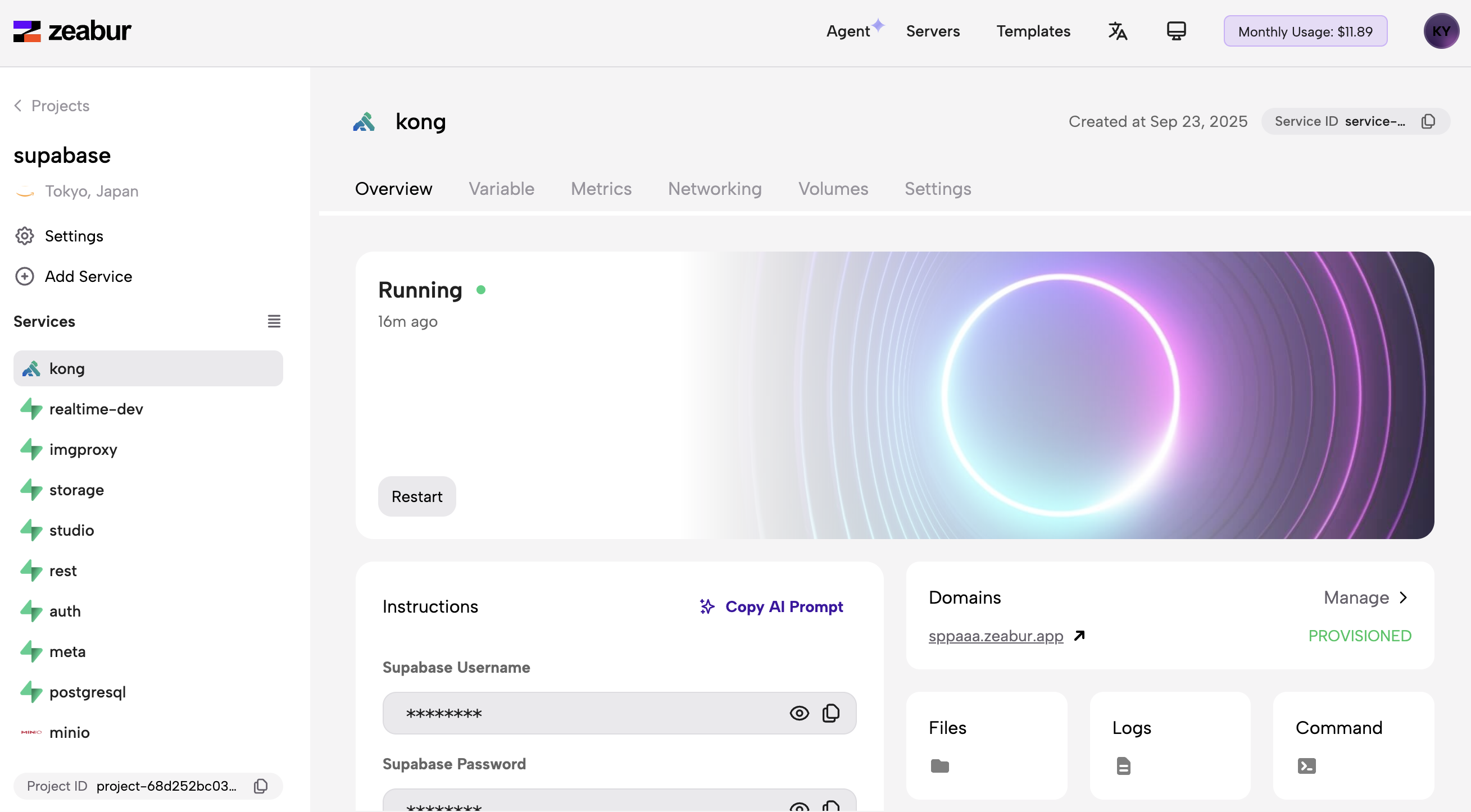
- Finalización de la implementación: Una vez que todos los servicios se están ejecutando, se lleva al usuario al panel de control del proyecto. La vista final muestra que el servicio "kong" está activo y la lista completa de servicios de Supabase implementados es visible a la izquierda, lo que indica una implementación exitosa.
Recursos adicionales
- Documentación de Zeabur Explore más sobre el uso de Zeabur para sus necesidades de implementación.